이번 포스트에서는 단순 연결 리스트( Linked List )에 대해 알아보겠습니다.
연결리스트는 배열(노드)을 하나씩 동적할당 한 후, 다른 배열(노드)와 연결해주는 방식의 자료구조입니다.
트리, 힙, 그래프 등등도 연결 리스트를 충분히 숙지해야 학습하는데 무리가 없기때문에 꼭 알아둬야 한다고 생각합니다.
🏳️ 연결 리스트와 배열
- 연결 리스트와 배열은 형태가 비슷하지만 각자 장단점을 지닙니다.
연결 리스트의 장점) 수정과 삭제가 자유롭다.
카드게임을 한다고 가정해 봅시다.처음 제 손에는 A, B, C 카드가 있습니다. 이것을 각각 그림으로 표현하면 다음과 같습니다.

여기서 D카드를 추가 하려면 어떻게 해야할까요? 이때 배열 크기는 3으로 고정해놨다고 가정해봅시다.

연결 리스트에선 새로운 노드(배열)을 동적 할당한 후 link를 연결만 해주면 되지만, 배열에서는 크기가 3이기 때문에 더 이상 추가할 수가 없습니다.(물론 realloc 함수를 쓰면 가능합니다.)
즉, 연결 리스트에선 배열 크기를 미리 정해주지않아도 된다는 장점을 가집니다.
그럼, 여기서 B카드를 제거한 후, C카드 부터 왼쪽으로 한칸씩 이동 시켜볼까요?

연결 리스트에선 B 카드를 가지고 있는 배열을 할당 해제 해준 이후, A의 link를 C로 연결해주면 됩니다.
배열에서도 B의 값을 C로 뒤집어 씌워 주면 됩니다만, 만약 이번 예시처럼 배열의 크기가 3개가 아닌, 천만개가 된다고 생각했을때, 원소들을 한칸씩 왼쪽으로 이동 시키는건 시간 복잡도가 꽤나 증가할 것으로 보이고, 또한 좋은 방법이 아니라고 생각됩니다.
배열의 장점) 접근성이 좋으며 속도가 빠르고, 메모리 관리가 편하다.
배열과 연결리스트 둘다 알파벳 순으로 카드를 저장해놨다고 가정해 봅시다. 이때 중복되는 카드는 없다고 보장될 때, B카드에 접근 하기 위해선 어떻게 해야할까요?

배열은 조건에 맞춰서 인덱스에 접근하면 원하는 값을 얻을 수 있습니다. 그러나, 연결리스트는 원하는 값을 찾기 위해서 처음부터 모든 리스트를 순회하기 때문에 속도가 느릴 수 밖에 없습니다.
물론, 각 노드의 주소를 저장하는 배열을 만들고, 때마다 그 배열에서 주소를 꺼내서 원하는 값에 바로 접근하는 방법도 있습니다만, 메모리 사용이 효율적이지 못할것입니다.
🏳️ 연결 리스트의 생성과 삽입
head 포인터를 만들어줍니다. (연결리스트를 순회하기 위해서 필요한 포인터, 주로 첫 원소를 head로 가지는 경우가 많음)

이때 head 포인터는 아무것도 가리키지 않는 상태로 생성합니다. (NULL을 가리키게 함.)
Case #1 ) 노드를 생성 하고 , head포인터를 연결 시켜줍니다.

1 - 노드를 동적 할당으로 생성합니다.
2 - 리스트 안에 원소가 없기 때문에 생성한 노드의 link 값은 아무것도 가리키지 않습니다.(NULL)
3 - head 포인터를 생성한 노드에 연결합니다.
4 - head 값을 반환해 줍시다.
이때 동적 할당한 최초의 원소는 다음 값을 가지지 않기때문에 link를 아무것도 가리키지 않는 상태(NULL)로 만들어 줍니다.
Case #1 - 1 ) 원소를 첫번째에 삽입 하고 싶으면, 노드를 생성 한 후 포인터들을 이동시켜 주면 됩니다.

이미 연결 리스트 안에 다른 원소가 존재 하고, 또한 제일 앞에 삽입 하는 것이 목적이기 때문에
1 - 노드를 동적 할당으로 생성합니다.
2 - 생성한 노드의 link를 현재 head인 원소에 연결합니다.
3 - head값을 생성한 노드로 변경해 줍니다.
4 - head 값을 반환해 줍시다.
Case #1 - 2 ) 원소를 첫번째가 아닌곳에 삽입 하고 싶으면, 노드를 생성 한 후 위와 비슷한 방식으로 포인터를 이동시켜 주면 됩니다.

이때 head와 삽입할 위치의 바로 직전 노드의 주소를 알아야 합니다.
1 - 노드를 동적 할당으로 생성합니다.
2 - 생성한 노드의 link를 그 직전 위치에 있는 노드의 link 값으로 변경 해줍니다. B의 link는 A를 가리키고 있고, C는 B와 A사이에 들어가려고 합니다. 즉 B->C->A로 리스트를 구현하고 싶기때문에 B의 링크를 그대로 복사하면 C->A의 구조가 만들어집니다.
3 - 삽입하려는 위치의 바로 직전 위치에 있는 노드의 link를 생성한 노드에 연결 해줍니다. 이때, B의 link는 A를 가리키고 있었지만, C를 가리키게 바뀌면서 자연스레 B->A의 link는 소멸(변경)됩니다.
4 - head 값을 반환해 줍시다.
이렇게 만들어 주면 결과적으로 B (head) -> C -> A -> NULL 를 가리키게 됩니다.
이를 코드로 나타내면 다음과 같습니다.
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
typedef struct Node
{
char data;
struct Node* link; // link가 가리키는건 Node 타입의 다른 노드기때문에 자기 참고 구조체를 사용합니다.
}Node;
Node* add_first(Node* head, char card)
{
Node* new = (Node*)malloc(sizeof(Node));
new->data = card;
new->link = head;
head = new;
return head;
}
Node* add(Node* head, Node* prev, char card)
{
Node* new = (Node*)malloc(sizeof(Node));
new->data = card;
new->link = prev->link;
prev->link = new;
return head;
}
int main(void)
{
Node* head = NULL;
Node* prev = NULL;
head = add_first(head, 'A');
head = add_first(head, 'B');
for (Node* i = head; i != NULL; i = i->link) // 직전 원소를 찾기 위해 head 포인터 부터 순회합니다.
{
if (i->link->data = 'A') // 'A' 직전에 넣는것이 목적이였기 때문에 prev 값을 업데이트 후 break
{
prev = i; // i의 다음값의 data가 'A'라면 우리가 찾는 'A'의 prev 값이 됩니다.
break;
}
}
head = add(head, prev, 'C');
for (Node* i = head; i != NULL; i = i->link) // head 포인터 부터 끝까지(NULL 아닐때까지) 순회합니다.
{
if (i->link == NULL)
{
printf("%c", i->data);
}
else
{
printf("%c->", i->data);
}
}
}
🏳️ 노드의 삭제
Case #1 ) 첫번째 원소를 삭제 하고 싶으면, head포인터를 이동시켜준후, 동적 할당 해제를 시켜주면 됩니다.

* 만약 head가 NULL을 가리킨다면(연결리스트에 원소가 아무것도 없다면) 작업을 수행하지 않습니다.*
1 - head 위치에 있는 노드를 removed로 정의 해줍니다.
2 - head 포인터를 removed->link 위치로 변경 시켜 줍니다.
3 - free(removed)로 할당 해제를 시켜줍니다.
4 - head 값을 반환해 줍시다.
Case #2 ) 첫번째가 아닌 원소를 삭제하고 싶으면, 위와 비슷한 방식으로 포인터를 이동시킨 다음 동적 할당 해제를 시켜주면 됩니다.

* 만약 head가 NULL을 가리킨다면(연결리스트에 원소가 아무것도 없다면) 작업을 수행하지 않습니다.*
이때 head와 삽입할 위치의 prev(바로 직전 노드)의 주소를 알아야 합니다.
1 - prev(직전 노드)->link로 removed 노드를 지정해 줍니다.
2 - prev의 link는 removed(지워지는 노드)가 향하는 link값을 가지게 변경해 줍니다.
3 - free(removed)로 할당 해제를 시켜줍니다.
4 - head 값을 반환해 줍시다.
삽입과 삭제 전체를 코드로 나타내면 다음과 같습니다.
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
typedef struct Node
{
char data;
struct Node* link; // link가 가리키는건 Node 타입의 다른 노드기때문에 자기 참고 구조체를 사용합니다.
}Node;
Node* add_first(Node* head, char card)
{
Node* new = (Node*)malloc(sizeof(Node));
new->data = card;
new->link = head;
head = new;
return head;
}
Node* add(Node* head, Node* prev, char card)
{
Node* new = (Node*)malloc(sizeof(Node));
new->data = card;
new->link = prev->link;
prev->link = new;
return head;
}
Node* delete_first(Node* head)
{
Node* removed;
if (head == NULL) // head 가 NULL이면 원소가 없으므로 NULL을 리턴해줍니다.
{
return NULL;
}
removed = head;
head = removed->link;
free(removed);
return head;
}
Node* delete(Node* head, Node* prev)
{
Node* removed;
if (head == NULL) // head 가 NULL이면 원소가 없으므로 NULL을 리턴해줍니다.
{
return NULL;
}
removed = prev->link;
prev->link = removed->link;
free(removed);
return head;
}
int main(void)
{
Node* head = NULL;
Node* prev = NULL;
head = add_first(head, 'A');
head = add_first(head, 'B');
for (Node* i = head; i != NULL; i = i->link) // 직전 원소를 찾기 위해 head 포인터 부터 순회합니다.
{
if (i->link->data = 'A') // 'A' 직전에 넣는것이 목적이였기 때문에 prev 값을 업데이트 후 break
{
prev = i; // i의 다음값의 data가 'A'라면 우리가 찾는 'A'의 prev 값이 됩니다.
break;
}
}
head = add(head, prev, 'C'); // prev의 다음 위치에 'C'를 추가합니다.
for (Node* i = head; i != NULL; i = i->link) // 'D'를 추가하기 위해 리스트의 끝까지 순회합니다.
{
prev = i;
}
head = add(head, prev, 'D'); // prev의 다음 위치에 'D'를 추가합니다.
head = delete_first(head); // 첫번째 원소인 'B'를 삭제합니다.
for (Node* i = head; i != NULL; i = i->link)
{
if (i->link->data = 'A') // 'A'값을 삭제하는게 목적이기 때문에 prev 값을 업데이트 후 break
{
prev = i; // i의 다음값의 data가 'A'라면 우리가 찾는 'A'의 prev 값이 됩니다.
break;
}
}
head = delete(head, prev); // prev의 다음 위치인 'A'를 삭제합니다.
for (Node* i = head; i != NULL; i = i->link) // head 포인터 부터 끝까지(NULL 아닐때까지) 순회합니다.
{
if (i->link == NULL)
{
printf("%c", i->data);
}
else
{
printf("%c->", i->data);
}
}
}
🏴 연결리스트의 활용 - 리스트 역순으로 만들기
아까 만든 연결리스트를 역순으로 정렬하고 싶으면 어떻게 해야 할까요? 새로운 연결리스트를 생성하면서 기존 노드들을 전부 지워야 할까요? 그렇지 않습니다. 포인터만으로도 충분히 역순으로 만들 수 있습니다.
STEP 1 ) 순회 포인터 3개를 지정합니다.

p포인터가 가리키는 것은 역순으로 만들 리스트 입니다.
q포인터가 가리키는 것은 역순으로 만들 노드 입니다.
r포인터가 가리키는 것은 역순으로 된 리스트 입니다.
1 - p포인터에 head값을 할당해줍니다.
2 - q포인터에 NULL값을 할당해줍니다.
STEP 2 ) r은 q, q는 p를 차례로 따라가게 만들어 줍니다.

1 - r포인터에 q포인터 값을 할당해 줍니다.
2 - q포인터에 p포인터 값을 할당해 줍니다.
3 - p포인터는 다음노드로 넘어가게 해줍니다.(p = p->link)
STEP 3 ) q->link의 값을 r포인터에 할당해줍니다.

STEP 3 ) STEP2 ~ STEP3의 과정을 p포인터가 NULL값이 아닐 때 까지(마지막 노드까지) 반복해 줍니다.

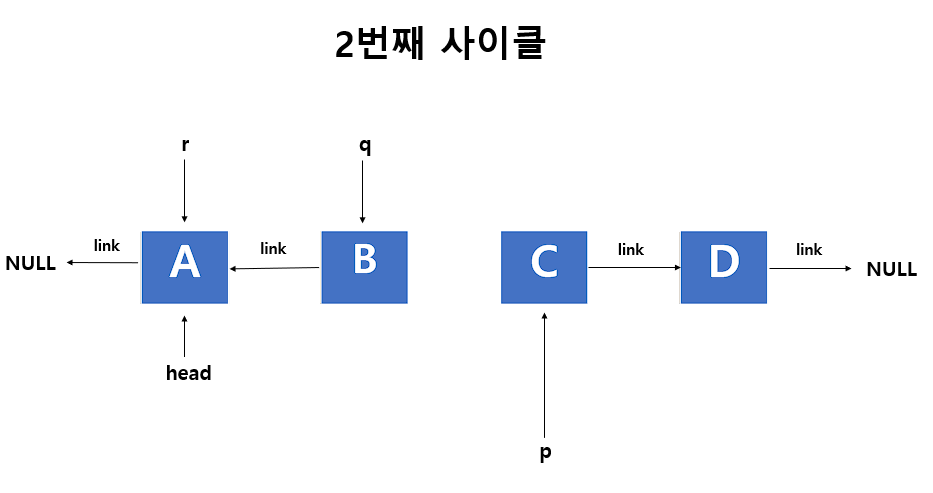




이때, q포인터를 head 포인터로서 return 해줍니다.
위 과정을 코드로 나타내면 다음과 같습니다.
#define _CRT_SECURE_NO_WARNINGS
#include <stdio.h>
#include <stdlib.h>
typedef struct Node
{
char data;
struct Node* link;
}Node;
Node* last = NULL; // prev 노드의 위치를 저장할 노드입니다.
Node* add_first(Node* head, char card)
{
Node* new = (Node*)malloc(sizeof(Node));
new->data = card;
new->link = head;
head = new;
last = new; // 직전 노드의 위치를 저장합니다.
return head;
}
Node* add(Node* head, Node* prev, char card)
{
Node* new = (Node*)malloc(sizeof(Node));
new->data = card;
new->link = prev->link;
prev->link = new;
last = new; // 직전 노드의 위치를 저장합니다.
return head;
}
Node* reverse(Node* head)
{
Node* p, * q, * r; // 순회에는 p, q, r 포인터가 필요합니다.
p = head; // p포인터는 초기에 head값을 가집니다.
q = NULL; // q포인터는 초기에 NULL값을 가집니다.
while (p != NULL) // p포인터가 끝에 도달할때까지 작업을 수행합니다.
{
r = q; // r포인터에 q포인터값을 대입합니다.
q = p; // q포인터에 p포인터값을 대입합니다.
p = p->link; // p->link로 p포인터를 다음 노드를 가리키게 합니다.
q->link = r; // q가 가리키고 있는 link의 위치를 r로 바뀌게 합니다.
}
return q; // 이제 q포인터가 head역할을 해주므로 새로운 head값을 return합니다.
}
int main(void)
{
Node* head = NULL;
head = add_first(head, 'A');
for (int i = 0; i < 3; i++)
{
head = add(head, last, 'A' + 1 + i);
}
head = reverse(head);
for (Node* i = head; i != NULL; i = i->link)
{
if (i->link == NULL)
{
printf("%c", i->data);
}
else
{
printf("%c->", i->data);
}
}
}
'백준 알고리즘' 카테고리의 다른 글
| 백준 알고리즘 #5 - 유클리드 호제법 (0) | 2024.02.28 |
|---|---|
| 백준 알고리즘 #4.2 - 원형 연결리스트, 이중 연결리스트 (0) | 2024.02.26 |
| 백준 알고리즘 #3 - 누적합 (0) | 2024.01.21 |
| 백준 알고리즘 #2 - 이진 탐색 (0) | 2024.01.11 |
| 백준 알고리즘 #1 - qsort (0) | 2024.01.09 |



